스마트폰, 카메라, CCTV, RGB-D, LiDAR 등 각종 비전기반 센서에서 촬영되는 멀티미디어 데이터에서 의미있는 정보를 추출하고, 분석하여 원하는 결과를 도출하기 위하여 고전적인 Image Processing 부터 Classification, Detection, Segmentation 등 다양한 Vision AI 기술을 활용하고 있습니다.
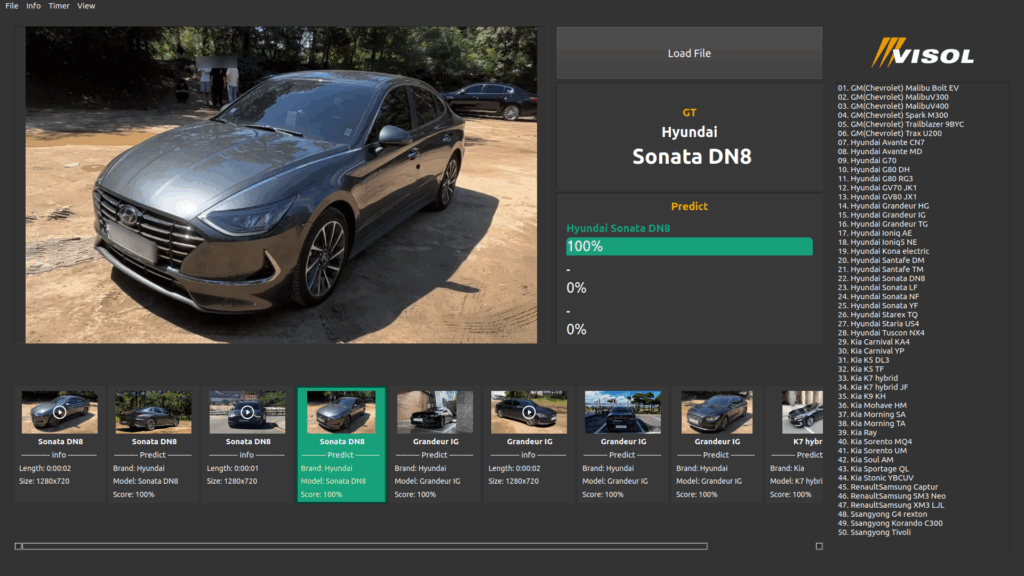
이미지 분류 (Image Classification)
Resnet, Mobilenet 등의 Classification AI 모델로 실시간으로 이미지의 class를 분류
기존의 분류 모델은 차, 트럭, 사람 등 넓은 범위의 class만 구분 가능하지만, 개발된 분류 모델은 차의 연식이나 모델까지 분류 가능
XAI(eXplainable AI)를 통해 분류 모델을 분석하여 AI 모델 정확도와 신뢰도 향상
객체 감지(Object Detection)
실시간으로 Object의 Location(Bounding Box)과 Class를 모두 추론
대다수의 Task에 적합한 AI 모델이며, 빠른 속도와 높은 정확도가 장점
Object Tracking을 적용하여 Object의 Trajectory와 속도, ID를 추정
다양한 Data Augmentation 기법을 적용하여 성능 고도화
이미지 분할 (Image Segmentation)
Pixel 단위로 이미지에 대한 정보를 학습하고 추론하는 기술
비전분야 AI 분석 기술 중 가장 연산량이 많아 성능을 요하는 기술
항공샷 혹은 로드뷰의 이미지에서 건물의 외형과 창문의 정확한 위치를 pixel단위로 추론해 줄 수 있음
영상 처리 (Image Processing)
Histogram Equalization으로 저조도 이미지를 개선
특정 색상의 객체만 선택하여 원하는 정보 추출
명도, 채도, 대비 등을 조절하여 Data Augmentation을 수행하고, AI 모델의 성능 향상