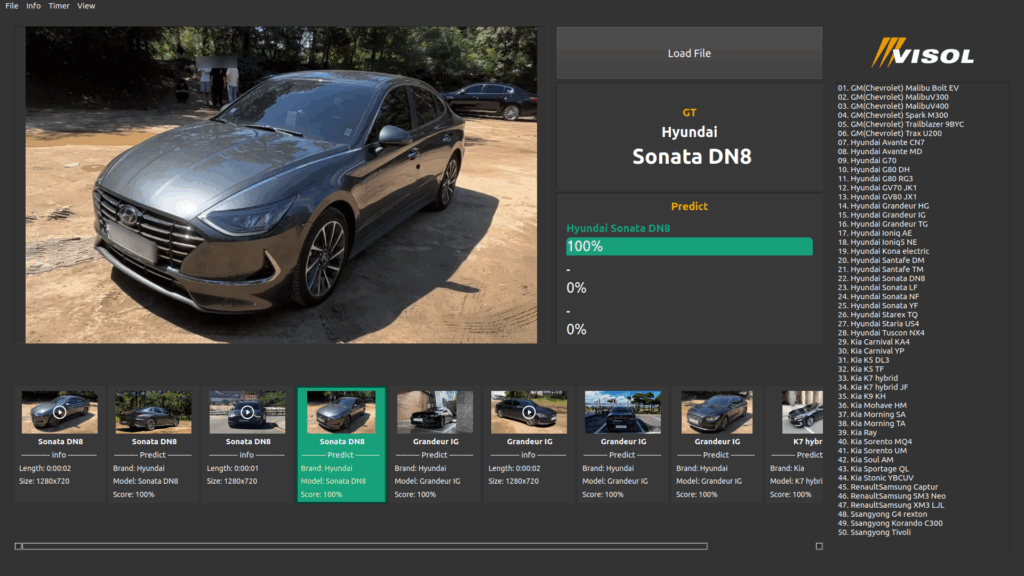
By extracting and analyzing meaningful information from multimedia data captured by diverse vision-based sensors—including smartphones, cameras, CCTV, RGB-D devices, and LiDAR—we leverage a comprehensive suite of Vision AI techniques, spanning classical image processing to advanced classification, detection, and segmentation, to achieve specific, impactful outcomes.